
High Throughput Sequence (HTS) data most commonly refers to short genetic sequences that have been digitized by a Next Generation Sequencer (e.g. Illumina MiSeq). HTS data is used in applications such as Personalized Medicine, Forensics, and Microbiology where a complete genetic sequence can provide useful insight. Current HTS data management and mining algorithms struggle to scale to the massive amounts of HTS data being generated as the cost of producing the data continues to fall and sequencer throughput increases. We are developing methods that extend existing solutions to process large volumes of HTS data in a manageable time frame by using more advanced index structures and leveraging massively parallel computing platforms.

The hardware technology, from processing units (e.g., multi-core and many-core/GPGPU technologies) to storage units (e.g., SSD technology), has undergone major advancements over the past decade, providing opportunities to address challenges with Big Data. In particular, Solid State Drives (SSDs) have emerged as a new type of secondary storage medium with both improved characteristics (e.g., access time) and new characteristics (e.g., parallel data retrieval) as compared to HDDs. In this project, we are focused on developing SSD-aware data management solutions that both are adapted to the improved features of SSD and can leverage the new features to achieve higher performance. For instance, we are developing SSD-aware index structures that can benefit from parallel retrieval capabilities of SSDs for high-performance implementation of spatial operators (e.g., spatial range and join queries) on massive spatial datasets.

The database field has been addressing problems of scale for some time, but the exponential growth in data volumes over the last decade has even the traditional database providers stumped.

Multivariate Spatiotemporal Sequences (MVS) can capture the concurrent motions of the moving objects (e.g., joints in skeletal data, players in a sports field, and vehicles in a transportation network). These sequences are ubiquitous and provide exceptional opportunities to derive interesting insights about the behavior of moving object masses. We are working toward introducing efficient and novel algorithms for mining, indexing and classification of patterns embedded in MVS data.

Data networks have evolved into a general model to capture relations such as in large web graphs, social and trust networks, biological networks, and communication networks. Due to the increase of scale of large spatial dynamic graphs, storing and processing connected data has become more challenging than ever before. Existing algorithms cannot efficiently process graph data with new representations and characteristics. In this project, we intend to improve performance of querying and mining on various graph datasets with uncertainty, spatial and/or dynamic characteristics. Currently, we are developing efficient solutions for reachability queries on uncertain bioinformatics datasets to interlink information in large scale biological datasets including sequence data, molecular data, gene expressions, protein data and pathway data. Reachability query can be applied to protein-to-protein interaction networks, for example, to identify the proteins that are in interaction with other known proteins.

Point Cloud Data (PCD) is a representation of objects in 2D and 3D using a (often) large cloud of points that embody the object. PCDs can be acquired by several technologies such as LIDAR and RGBD cameras (e.g., Microsoft Kinetic), and are used in a variety of modeling and mapping applications, e.g., dike and flood modeling, building mapping, SLAM (Simultaneous Localization And Mapping). Management and mining of PCDs is challenging due to both large size/volume of the data and high rate of data generation. In this project, we develop efficient dynamic index structures for real-time querying of PCDs to enable effective management and mining of this type of Big Data.
The COPDGene Study is a national project that investigates the underlying genetic factors of Chronic Obstructive Pulmonary Disease (COPD). As part of this data-driven study, large-scale datasets of various types are generated, including gene expression data, biomarkers, metabolites, omics data, CT scans, etc. At BDLab, we are developing a suite of novel tools for efficient data integration, querying, and mining of the multi-modal and high-dimensional COPD data. This project is performed in collaboration with the National Jewish Hospital and the Biostatistics and Informatics Department at the Anschutz Medical Campus, University of Colorado Denver.
Download the application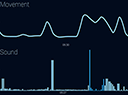
Biomedical signals such as EEG, EMG, and EOG offer useful details to study and monitor physiological and mental status of individuals. These signals embed information that can drive a variety of applications such as sleep quality monitoring and sleep disorder diagnosis, eye tracking, neuro marketing, and distracted driving, to name a few. In this project, we intend to develop an open source generic framework that provides a set of primitive operators for mining and analysis of the biomedical signals collected by our mobile in-ear sensor. As a focus application, we are exploring use of this framework for sleep disorder diagnosis. Toward this end, first we are introducing custom feature extraction, feature selection and data classification algorithms to identify relevant signatures of sleep stages to be able to classify sleep stages and characterize sleep cycles. Next, we use our framework to perform causality analysis toward identification and isolation of the impact of environmental factors (such as temperature, humidity, light, etc.) on sleep cycle. As the last step, we will use our framework to diagnose sleep disorders by detecting the disease signatures in isolation from environmental factors. This project is performed in collaboration with the Mobile Networked Sensing Laboratory at University of Colorado Denver.

EHR (Electronic Health Record) and EMR (Electronic Medical Record) generate massive collection of health and medical data which provide unprecedented opportunities to improve quality of service in healthcare and medical sectors. We develop technologies to realize these opportunities. In particular, currently we are developing a suite of solutions for effective search and pattern mining in massive claim data (aka CMS data) collected by private and governmental medical insurance providers (including Medicare and Medicaid). This suite will support and enable applications such as in-situ diagnosis based on best practices and historic data, personalized and continuous continued medical education (CME), clinical pathway adherence measurement, etc. We model CMS data as rich sequence of events, termed MES (Medical Event Sequence) which include a variety of spatial, temporal and clinical information (e.g., ICD, CPT, and HCPCS), and we develop efficient query and analysis data structures and algorithms for operators such as exact and approximate subsequence matching, sequence subtyping, etc. This project is performed as a collaboration between Medical Campus and Business School at the University of Colorado Denver.
Transportation network (or road network) is a prime example of spatiotemporal networks, and ITS (Intelligent Transporation System) uses data-driven solutions to enhance the utilization of such networks. Given the multidimensional and evolving nature of these networks, enabling data-driven query and analysis operators on such networks is challenging. In the past, we have introduced a variety of novel operators for efficient querying and mining of transportation data in support of ITS. Currently, we are developing an alternative route-planning solution to optimize utilization of the transportation network by taking a "system optimal" approach as compared to the typical route planning approach that results in Nash equilibrium at best. This project is sponsored by the Mountain Plains Consortium (MPC) and the Colorado Department of Transportation (CDOT).

Chatbots or voice assistants are becoming the de facto interface in numerous applications. However, their interactions are recognized by human users as “robotic”, limiting their appeal and usability. In this project, we focus on developing machine learning and NLP based solutions that enable introducing humanlike conversational models for chatbots. Toward this end, our current solutions capture the context of the conversation in real time during a conversational interaction. The context captured can then be used to create personalized responses that are tailored to the specific preferences of each individual user of the system. This research project is performed in collaboration with School of Medicine, at the Anschutz Medical Campus, University of Colorado Denver.
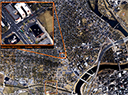
Wide Area Aerial Surveillance (WAAS) is referred to the process of event detection by analysis of the imagery/video data collected via remote sensing. Given the complexity of events on the one hand and real-time requirements of WAAS, pure content-based analysis falls short of monitoring complex events on-the-fly. With this project, we pursue a two phase data-driven approach to address this challenge toward enabling real-time complex event detection with WAAS, where at the first phase existing content-based analysis approaches are utilized to detect and store “simple” events (so-called incidents), and at the second phase real-time complex event detection is achieved by formulating “context-aware” queries that can identify and correlated the relevant incidents to frame the complex events (i.e., by connecting the dots). Toward this end and to enable robust, scalable, and real-time context-aware query processing, customized data model, spatiotemporal algebra, query language, and query processing solutions must be introduced. This project is performed as a collaboration between IRIS and BDLab.